
How to Fuzz-Test PROFINET-Enabled Devices
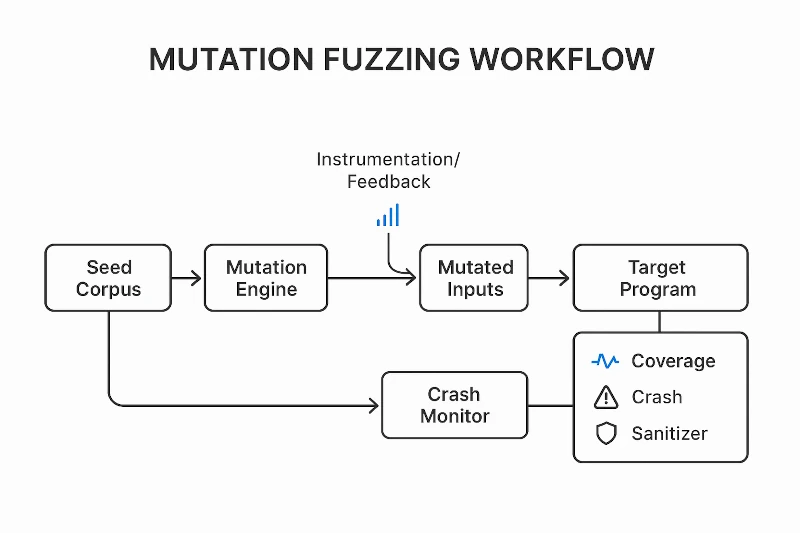
PROFINET fuzzing requires protocol-aware, stateful testing of DCP, RT frames, records, alarms, and topology data to uncover crashes, misconfigurations, and resilience gaps, with Penzzer enabling structured reproducible campaigns.


